

The recently released Deepseek-R1 model family has brought new excitement to the AI community, so that enthusiasts and developers have been able to perform state-of-the-art inference models with problems, mathematics, and chord functions. Local PC.
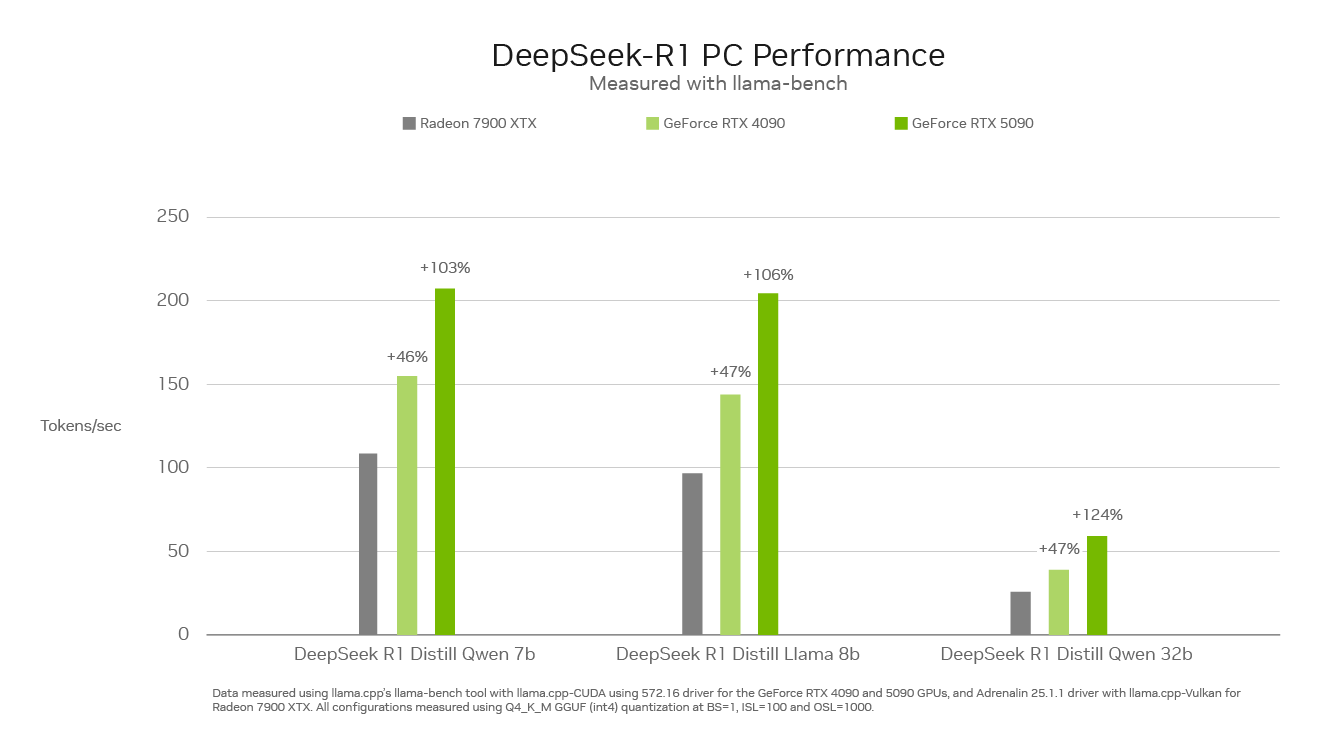
With a maximum of 3,352 trillion in AI horsepower, the NVIDIA GeForce RTX 50 Series GPU can execute the distillation model DeepSeek family faster than anything else in the PC market.
A new class model for that reason
Progress model is a new class of a large language model (LLM) that spends more time on “thinking” and “reflection” to solve complex problems while explaining the steps required to solve the task.
The basic principle is that, just like how humans tackle problems, they can solve problems with deep thinking, inference, and time. LLM can get better results by spending more time and thus calculating the problem. This phenomenon is known as a test time scaling, and the model is dynamically assigned computing resources while inferrating reason through problems.
Printing models can improve the user experience of the PC by understanding the user’s needs, performing action on behalf of them, and providing feedback on the model thinking process. Complex math problems, code debugging, etc.
Difference of DeepSeek
The distillation model Deepseek-R1 family is based on a mixture of large 67.1 billion parameters (MOE) models. The MOE model is composed of multiple small expert models to solve complex problems. The DeepSeek model divides the work further and allocates subtasks to smaller experts.
DeepSeek has adopted a technology called distillation from a large Deepseek 67.1 billion parameter model to build a family of six small student models (the scope of 15 to 70 billion parameters). Large-scale Deepseek-R1 67.1 billion parameter model inference functions are taught by smaller lamas and QWEN students, and as a result, powerful and smaller inference models are located on a high-speed RTX AI PC. Was born.
RTX peak performance
The reasoning speed is important for this new class inference model. The GeForce RTX 50 Series GPU, built with a dedicated fifth generation tensor core, is based on the same NVIDIA BLACKWELL GPU architecture that promotes the world -leading AI innovation in the data center. RTX fully accelerates DeepSeek and provides the largest inference performance in PCS.
Experience DeepSeek with RTX with popular tools
NVIDIA’s RTX AI platform is a feature of more than 100 million NVIDIA RTX AI PCS, including those that provide AI tools, software development kits, models of the GeForce RTX 50 Series GPU. Open access to.
The high -performance RTX GPU enables the use of the AI function without Internet connection, does not need to upload confidential materials or disclose queries to online services, so it provides a decrease and an increase in privacy. Masu.
Experience the power of DeepSeek-R1 and RTX AI PCS through vast software eco-systems such as Llama.cpp, OLLAMA, LM Studio, Anyllm, Jan.ai, GPT4ALL, Openwebui. In addition, the model is fine -tuned with custom data using Unsloth.