


Some researchers believe that AI systems will soon reach human-level intelligence. Others think it’s far.Credit: Getty
Technology company OpenAI made headlines last month after its latest experimental chatbot model, o3, received high scores in tests marking progress toward artificial general intelligence (AGI). OpenAI’s o3 score of 87.5% exceeds the previous highest score for an artificial intelligence (AI) system of 55.5%.

How close is AI to human-level intelligence?
This is a “true breakthrough,” said the author of the Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI)1 in 2019 while working at Mountain View, Calif.-based Google. said AI researcher François Cholet, who created the test called. Although high test scores do not mean that AGI, broadly defined as a computing system that can reason, plan, and learn skills like humans, has been achieved, o3 recognizes that reasoning and learning is “Absolutely” has the ability to do so, Chollet said. “It has tremendous generalizability.”
Researchers have been amazed by o3’s performance in a variety of tests and benchmarks, including the extremely difficult FrontierMath test published by virtual research institute Epoch AI in November. “This is very impressive,” says David Lane, an AI benchmarking researcher at the Berkeley, Calif.-based Model Evaluation and Threat Research Group.

ChatGPT breaks the Turing test — the race is on for new ways to evaluate AI
However, many, including Rein, caution that it is difficult to determine whether the ARC-AGI test truly measures AI’s reasoning and generalization abilities. “There were a lot of benchmarks that were meant to measure things that were fundamental to intelligence, but it turned out that they weren’t,” Lane said. The search for better tests continues, he says.
San Francisco-based OpenAI hasn’t disclosed how o3 works, but the system comes on the heels of the company’s o1 model and uses “chain of thought” logic to create a series of inference steps. Solve problems by engaging yourself in dialogue. Some experts believe that o3 generates a series of different thought chains that help squeeze the best answer from a variety of options.
Chollet, who is now based in Seattle, Washington, says that giving yourself more time to elaborate on your answers during a test can make a big difference in your results. But o3 comes at a huge cost. Each task on the ARC-AGI test took an average of 14 minutes in its high-score mode and likely cost thousands of dollars. (Cholet said computing costs are estimated based on how much OpenAI charges customers per token or word, which is determined by factors such as power usage and hardware costs.) This “raises sustainability concerns,” said Xiang Yue of Carnegie Mellon University. Pittsburgh, PA, is researching large-scale language models (LLMs) to power chatbots.
smart overall
Although the term AGI is often used to describe computing systems that meet or exceed human cognitive capacity across a wide range of tasks, no technical definition exists. As a result, there is no consensus on when AI tools achieve AGI. Some say that moment has already arrived. Some say it’s still a long way off.
Many tests have been developed to track progress toward AGI. Some, including Rein’s 2023 Google-Proof Q&A2, are aimed at evaluating the performance of AI systems on doctoral-level scientific problems. OpenAI’s 2024 MLE Bench pits AI systems against 75 challenges hosted on Kaggle, an online data science competition platform. Challenges include real-world problems such as translating ancient scrolls and developing vaccines3.
Source: Reference 1
A good benchmark should avoid many problems. For example, it’s important that the AI doesn’t see the same questions during training, and questions should be designed so that the AI can’t use shortcuts to cheat. “LLM is good at exploiting subtle text cues to arrive at an answer without doing any real inference,” Yue says. Tests should ideally be as messy and noisy as real-world conditions, he added, while also setting energy efficiency goals.
Yue led the development of a test called the Massive Multidisciplinary Multimodal Understanding and Reasoning Benchmark (MMMU) for Expert AGI. This test asks the chatbot to perform college-level visual-based tasks, such as interpreting music scores, graphs, and schematics4. According to Yue, OpenAI’s o1 holds the current MMMU record at 78.2%, compared to the best human performance of 88.6% (o3’s score is unknown).
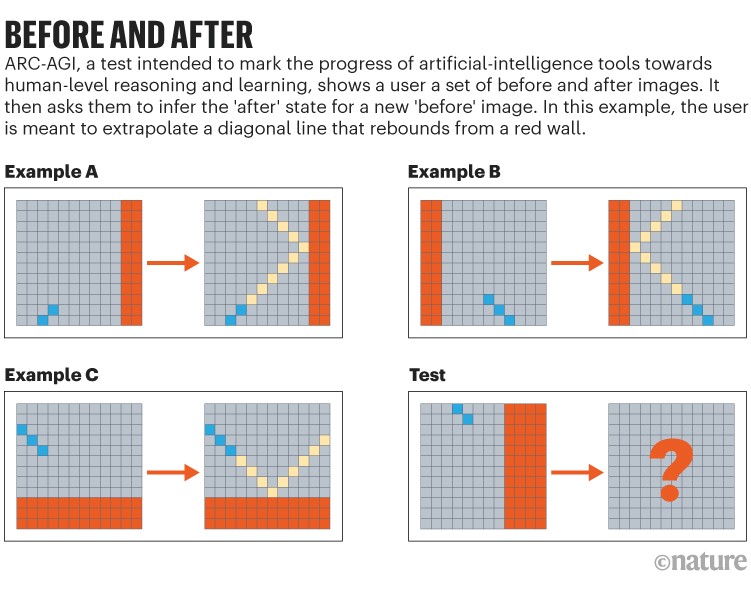
In contrast, ARC-AGI relies on the basic skills of mathematics and pattern recognition that humans typically develop during early childhood. It provides test takers with a demonstration set of before and after designs and asks them to infer the ‘after’ state of the new ‘before’ design (see ‘Before and After’). “We like the ARC-AGI test from a complementary standpoint,” Yue says.