


The United States has found it necessary to impose export controls on massively parallel computing engines to stop China from buying them and using them to build supercomputers, but each time it did so, it was already too late to have a long-term impact on China’s ability to run the advanced HPC simulations and AI training workloads that it feared such computing power would enable.
If the goal was to slow the competition down a little, then the export restrictions imposed by the US Commerce Department were successful, but in the long run, the restrictions forced US-based vendors (in this case Intel and NVIDIA) to sacrifice revenue and visibility into supercomputing taking place inside China, in exchange for perhaps years of delays and inconvenience to Chinese HPC centers, and now the hyperscalers and cloud builders.
Is it worth the trouble all of this causes?
That’s up for debate, and the debate started anew this morning when The Wall Street Journal published a story saying that Huawei Technologies’ chip design subsidiary, HiSilicon, is preparing to bring its third-generation Ascend 910 series GPUs to market in October and could sell perhaps as many as 1.4 million of these devices to hyperscalers and cloud builders in 2025. These are China’s Big Four — Baidu, Tencent, Alibaba, ByteDance and others — who can’t get serious AI accelerators from Nvidia, AMD, Intel and the like because of U.S. export restrictions that took effect in fall 2022 and then tightened last year.
Of course, that’s a lot of GPU acceleration. And even if these third-generation Ascend 910C devices from HiSilicon offer only a fraction of the capacity of the current “Hopper” H100 or Nvidia’s announced-but-not-yet-shipped “Blackwell” B100 GPUs, it’s enough to do interesting work in AI and probably HPC as well. How do we know? Because OpenAI trained a GPT 4.0 model on a cluster of 8,000 Nvidia “Ampere” A100 GPUs nearly two years ago. That means that if HiSilicon can beat the A100, it’s fine for Chinese AI researchers to use it, as long as they have access to more power and probably more funding to get a certain amount of compute to do their training runs.
I’ve seen this export control movie before.
In October 2010, when the Tianhe-1A supercomputer at the National Supercomputer Center in Tianjin, China, was unveiled as the world’s fastest floating-point floppy, it was developed by the National University of Defense Science and Technology (NUDT) and consisted of 14,336 Intel Xeon processors and 7,168 Nvidia Tesla M2050 GPU coprocessors, with the peak performance of all these computational engines being an astounding 4.7 petaflops.
The Tianhe-2 kicker at the National Supercomputer Center in Guangzhou was also a hybrid machine, but it was made up of 16,000 Intel Xeon E5 processors and 16,000 “Knights Corner” Xeon Phi many-core accelerators (essentially GPU-like accelerators with powerful vector engines connected to stripped-down X86 cores).
When Chinese HPC centers decided to build their much more powerful Tianhe-2A machines based on Intel’s upcoming and much more powerful “Knights Landing” Xeon Phi chips, the US government had a headache, since many of the US’s larger HPC centers were also planning to use these computing engines. So the Commerce Department banned Intel from selling Knights Landing chips to certain Chinese HPC centers. So the Tianhe-2A machine had 17,792 nodes, each with an Intel Xeon CPU and a home-made Matrix-2000 accelerator that used an array of DSPs as its math engine. (We believe this is actually a 256-bit vector Arm core, and has nothing to do with DSP, and we said so when the Tianhe-2A was announced in September 2017.) The machine had a peak performance of just under 95 petaflops at FP64 precision, and the export restrictions did nothing but force China to develop its own accelerators, which it did quickly.
A new set of export restrictions on Nvidia, AMD, and Intel accelerators for HPC and AI workloads will not be effective in stifling progress in China, but it will be effective in encouraging domestic innovation, which is in any case China’s ultimate goal, as we have noted in the past.
We haven’t paid much attention to this export control nonsense, but to help sort it out, we’ve put together a table comparing Nvidia’s regular A100 and H100 accelerators with the compression accelerators the company has been trying to sell for the past two years. And, just for fun, we’ve compared HiSilicon’s Ascend 910A and Ascend 910B GPUs to them, and tried to guess what the Ascend 910C might be like. Take a look:
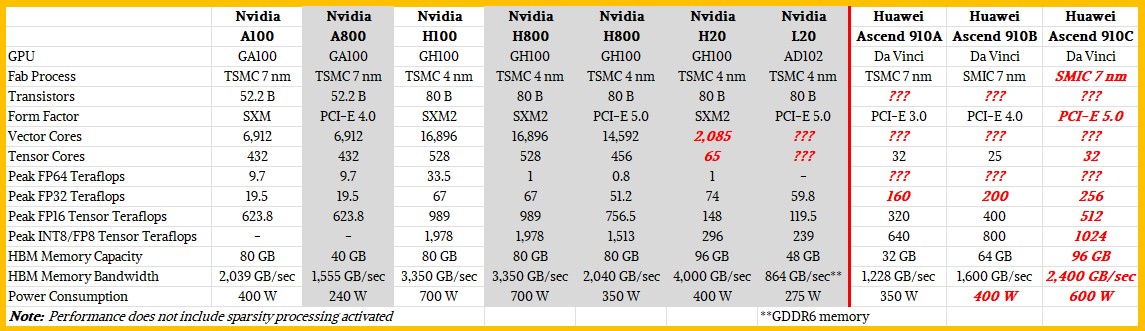
What Nvidia actually did with the A800 two years ago was cut the GPU memory capacity in half, reduced the memory bandwidth by 25 percent, and switched to the PCI-Express 4.0 form factor, limiting the shared memory footprint of these devices to two GPUs over NVLink, rather than eight GPUs over NVLink and a bank of NVSwitch ASICs in the middle. All other feeds and speeds on the A800 were the same as the regular A100. Performance was supposedly cut, but not by a lot.
With the H100, GPU performance increased by 1.6x to 3.4x in most metrics, but Nvidia initially kept memory capacity at 80GB and increased memory bandwidth by 64 percent. Power consumption increased by 75 percent.
Last year, two versions of the H800 were released for China. The SXM version, which can be linked with NVSwitch, was limited to 1 teraflops with FP64 precision, and otherwise remained largely unchanged. The PCI-Express version of the H800 had some cores deactivated, resulting in reduced performance and a 39% memory bandwidth limit. The US government decided late last year that this wasn’t enough, and tightened the restrictions to further raise the computing cap, but increased HBM memory capacity and bandwidth (albeit very inconsistently). The H20 in the SXM2 form factor is not particularly powerful, and the L20, based on the “Lovelace” GPU architecture, is even worse. It’s a wonder Nvidia even bothers.
That’s probably because U.S. export controls forced HiSilicon to switch from Taiwan Semiconductor Manufacturing Corp. as its foundry to Semiconductor Manufacturing International Corp., which is still learning domestically.
I didn’t know much about HiSilicon’s “Da Vinci” GPU architecture, but after some research I found this graph:

That means there are 32 of these Da Vinci cores, each with 4,096 FP16 Multiply-Add (MAC) units, 8,192 INT8 cubes, and a 2,048-bit vector unit capable of performing INT8, FP16, and FP32 operations.
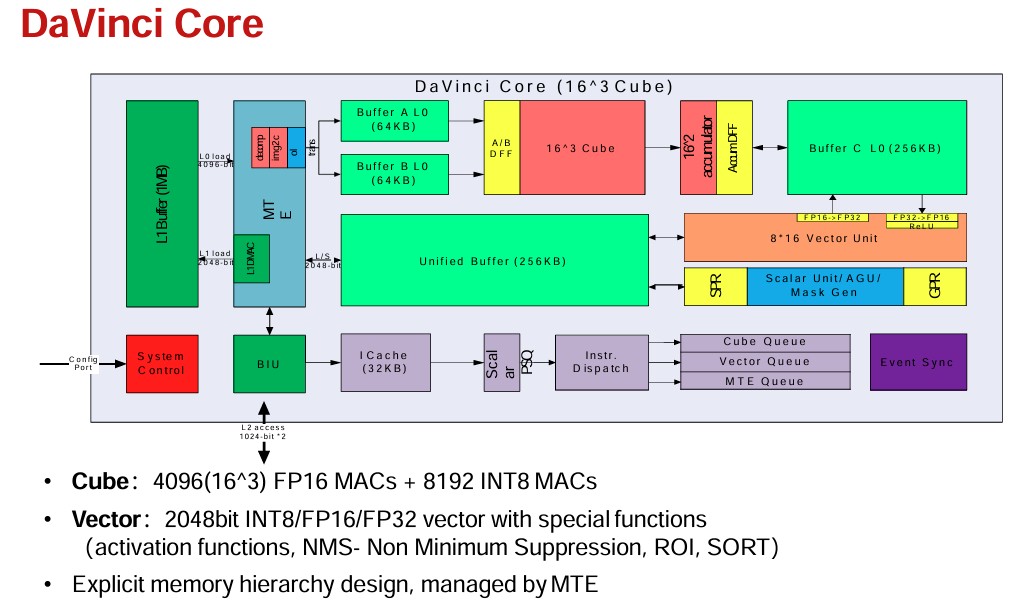
The Ascend 910A line, which achieved reasonable yields on TSMC’s N7 7-nanometer process, shipped between 30 and 32 Da Vinci cores, which is not bad.
But then China had to switch to SMIC as their foundry. Various reports said that the SMIC 7-nanometer process had significantly lower yields, making it very hard to boost performance even with increased core counts and clock speeds. But for top-bin parts, HiSilicon made it happen.
The Ascend 910B will likely have a 6 x 6 grid of Da Vinci cores, for a total of 36 cores. The 20- to 25-core parts have very low yields, to be sure, but we believe the Ascend 910C, due out later this year, will add two more HBM memory banks to the design, potentially improving yields and bringing it back up to the 32 cores advertised on the original HiSilicon GPU from five years ago.
Of course, it’s all speculation.
But what’s not speculation is that the crimped Hopper GPU and the possibly crimped Blackwell GPU that Nvidia has in the works won’t compete well enough on the specs front, so it all comes down to yields, price, availability and demand. We’ll see soon enough.
There’s no doubt that China could easily consume millions of Ascend 910C accelerators. But can SMIC manufacture them, and at what price? If not, the Nvidia H20, B20, or even L20 may be sufficient for many customers.
The funny thing is, without the US government’s export restrictions, Nvidia would have almost all of the GPU business in China today, as well as the rest of the world, with the revenue coming back to the US and being taxed, and Chinese companies would buy Nvidia’s GPUs even though China wants domestic IT suppliers, because Nvidia is almost always the easiest and best option right now, taking into account all the hardware and software.
In some ways, the United States is playing into China’s hands, and either way, China will ultimately get what it wants — and it can get it precisely because it has the financial wherewithal to create the technological capabilities it has copied (and, in some cases, licensed, borrowed, or stolen) from its environmental and political rivals.
The world is a mess, and we hate no-win scenarios as much as Captain Kirk.
