

Editor Note: This article was originally released on November 15, 2023, but was updated.
To understand the latest progress of generated AI, imagine a court.
The judge will hear and decide on a lawsuit based on the general understanding of the law. Occasionally, cases such as medical malfunctions and labor disputes may require special expertise, so the judge sends a court clerk to the lawyen and searches for a specific case that can be quoted.
Like a good judge, a large language model (LLM) can respond to various human queries. However, in order to provide a prestigious answer based on a specific court or similar procedure, it is necessary to provide that information to the model.
The AI court clerk is a process called the searched generation, or a process called RAG.
A method named “rag”
Patrick Lewis, the main author of the 2020 dissertation that created the term, apologized for explaining hundreds of papers and how to continue to increase over the dozens of commercial services.

In an interview in Singapore, Lewis shared the database developer’s regional conference and ideas, “If we know that our work will be very large, we think more about the name. It would have been.
“We were always planning to have a better sound name, but no one had a better idea when the time came to write,” Luis said.
So what is the searched high -generation (RAG)?
The searched generation is a method for enhancing the accuracy and reliability of the generated AI model using the information obtained from a specific data source.
In other words, fill the llms mechanism gap. Under the bonnet, LLM is a neural network and is usually measured by the number of parameters included. LLM parameters essentially represent a common pattern of how humans use words to form a sentence.
With its deep understanding, which is sometimes called parameterized knowledge, LLMS helps a general prompt. However, we do not provide services to users who want to dig deeper into specific types of information.
Combination of internal external resources
Lewis and colleagues have developed high -generation generations searched to link the generated AI services to external resources, especially the latest technical details, and abundant resources.
This paper can be used to actually connect with former Facebook AI Research (now Meta AI), University College London, and New York University for actually connecting. It is called “Adjustment recipe”. External resources.
Construction of user trust
Users can confirm the request for the generated generation that can be quoted, like a footnote in a research paper, to provide the source of a model that can be quoted. It builds trust.
In addition, this method helps the model to resolve the ambiguity of Uzak Eli. It also reduces the possibility that the model is very plausible but incorrect, and the phenomenon called hallucinations.
Another major advantage of RAG is that it is relatively easy. A blog by Lewis and the three papers stated that the developer could implement the process with only five lines of code.
This makes the method faster and cheaper than re -training the model using additional datasets. And the user can hot swaps on the new source on the spot.
How to use people ragged
By generating searched, users can basically talk with the data lipfish and open new types of experiences. This means that RAG applications can be multiple times the number of datasets available.
For example, the generated AI model that complements the medical index can be an excellent assistant for doctors or nurses. Financial analysts will benefit from assistants linked to market data.
In fact, almost all businesses can be changed into technical or policy manuals, videos, or logs that can enhance LLM. These sources enable use cases such as customer and field support, employee training, and developers productivity.
A wide range of possibilities is why AWS, IBM, Gleans, Google, Microsoft, NVIDIA, Oracle, and Pinecone use RAG.
Start the searched high -generation generation
RAG’s NVIDIA AI Blueprint helps developers to build pipelines and connect AI applications to enterprise data using the industry -leading technology. This reference architecture provides developers the foundation for building a scalable and customized search pipeline to provide high -precision and throughput.
Blue photos can be used as they are or combined with other NVIDIA blueprints in advanced use cases, including digital humans and AI assistants. For example, AI Assistant Blue Copy allows the organization to build an AI agent that can quickly increase customer service operation with AI and RAG.
In addition, the developer and the IT team will try a free NVIDIA LaunchPad lab for building AI chatbots in RAG, enabling quick and accurate response from enterprise data.
All of these resources use NVIDIA NEMO RETRIEVER. This provides major large -scale search accuracy and NVIDIA NIM microservices to simplify the safe and high -performance AI deployment across the cloud, data center, and workstations. These are provided as part of the NVIDIA AI Enterprise Software Platform to accelerate the development and development of AI.
To get the optimal performance for RAG workflow, you need a large amount of memory and calculation to move and process data. NVIDIA GH200 Grace Hopper Superchip with 288GB high -speed HBM3E memory and 8 -peta computing can provide 150 times speeding up using the CPU.
Once a company is familiar with RAG, you can create a wide range of assistants to support employees and customers by combining various ready -made or custom LLMs with internal or external knowledge.
RAG does not require a data center. LLMS debuts on Windows PCs thanks to NVIDIA software, which allows all kinds of applications to access laptops.
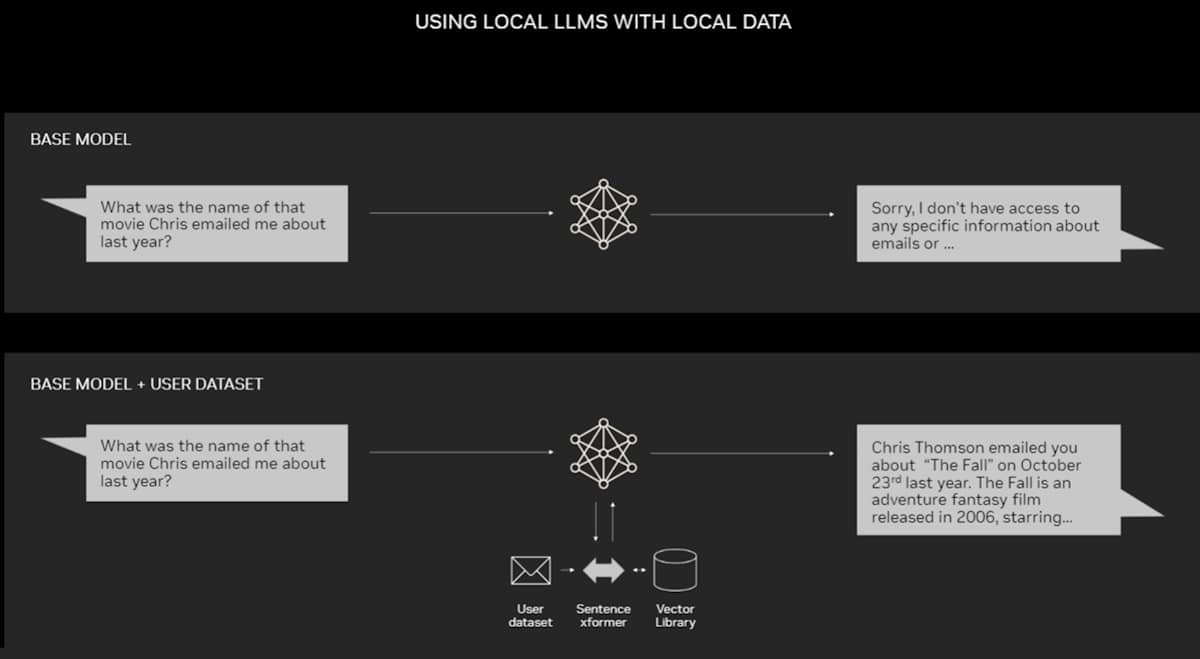
The PC equipped with the NVIDIA RTX GPU can now run some AI models locally. By using RAG on a PC, users can link to personal knowledge sources, even in e -mail, memo, or articles. After that, the user is convinced that all data sources, prompts, and response remain private and secure.
Recent blogs provide a ragged example of Windows accelerated by Tensorrt-LLM to get better results.
Ragged history
The root of the technique dates back to the early 1970s. At that time, the researcher of information search first prototypes using an application that uses natural language processing (NLP) to access text with narrow topics such as baseball and questions the answer system.
The concept behind this kind of text mining remains quite constant for many years. However, the machine learning engine that drives them has increased significantly, and its usefulness and popularity are increasing.
In the mid -1990s, ASK JEEEVES Service and Now ask.com answered questions at a well -dressed Barrett mascot. Watson of IBM became a celebrity on TV in 2011. Game show.
Today, LLMS has raised the system to answer questions to a completely new level.
Inspired from London’s lab
Lewis acquired a Ph.D. in the London Universi College NLP and worked in a meta in the new London AI Lab, so a 2020 original paper arrived. The team was looking for a way to pack more knowledge into LLM parameters and used a benchmark developed to measure the progress.
Based on the previous method, a group inspired by a publicly researcher in Google, “I had this persuasive vision of a trained system with a search index in the center, so I needed text output. Lewis recalled. 。

The first result was unexpectedly impressive when Lewis connected a promising search system from another metal team to an advanced work.
“I showed a supervisor, and he said,” Oops, depriving you, this kind of thing doesn’t happen much. These workflows may be difficult to set up correctly for the first time. ” He said.
Lewis also praised the great contributions from Ethan Perez and Duwes Kierra, a team member of the New York University and Facebook AI research.
Once completed, the work performed with the NVIDIA GPU cluster has shown how to make the generated AI model more authoritative and reliable. Since then, it has been quoted by hundreds of papers, amplifying and expanding the concept of what has been an active field of research.
How the searched generation works
At a high level, the following shows how the searched generation works.
When a user asks LLM, the AI model can send a query to another model, convert it into numerical format, and read the machine. The query numerical version is sometimes called embed or vector.
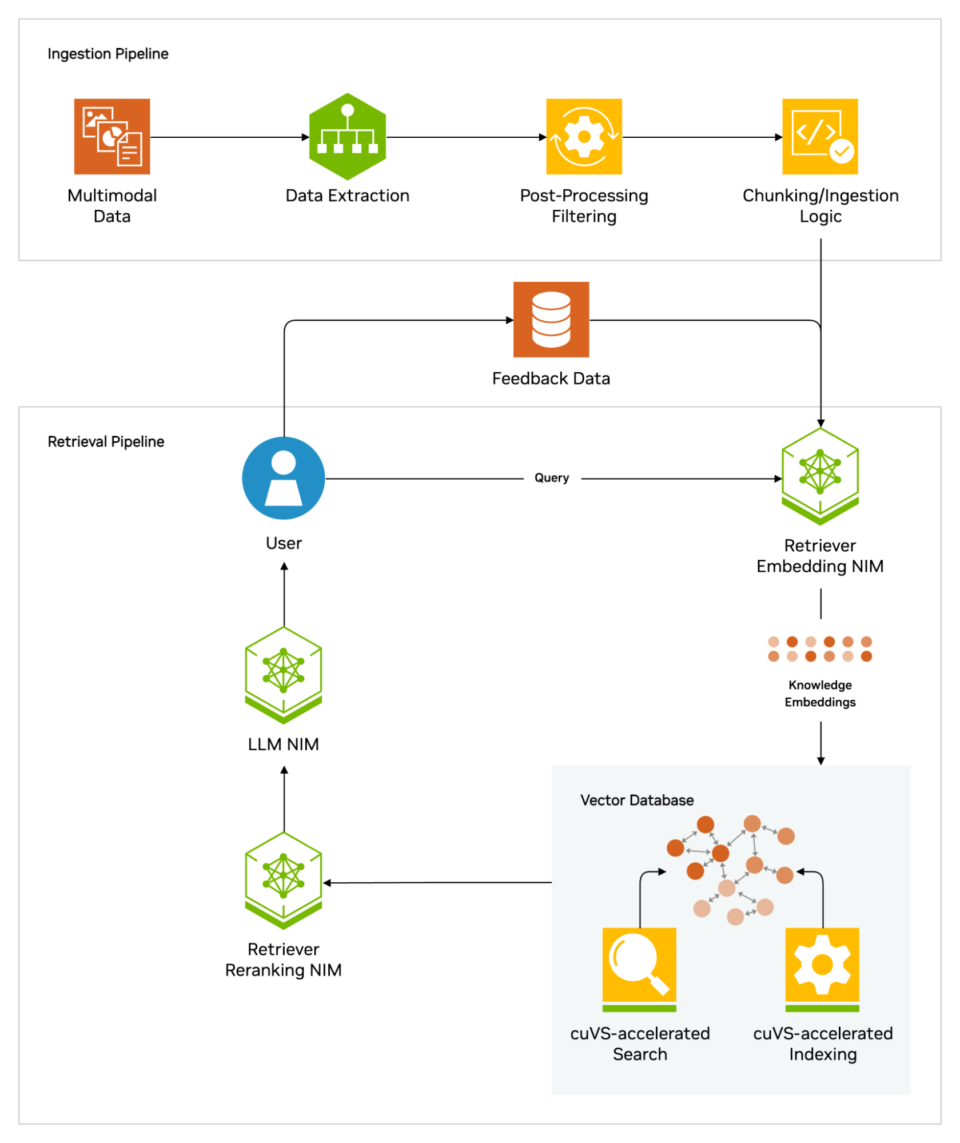
The embedded model compares with the vector of the Knotge -based mechanical ready index that can use these numbers. If you find a match or multiple matches, acquire related data, convert it to a human -can -readable word, and pass it to LLM.
Finally, the LLM may quote the source where the embedded model was found in combination of the acquired words and the unique response to the query with the final answer to the user.
Keep the source up to date
In the background, embedded models are used for new and updated knowledge that continuously created and updated the imable indexes that were sometimes called vector databases.
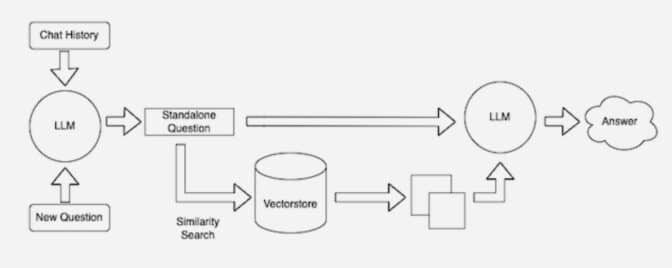
Many developers believe that open source library, LanguChain, is particularly useful for implanting models and knowledge base with LLMS. NVIDIA uses LanguChain for reference architecture for searching for searched.
The Langchain community provides a unique explanation of the RAG process.
The future of the generated AI is in Agent AI. Here, LLMS and knowledge base are dynamically adjusted to create autonomous assistants. These AI -drive -type agents can enhance decision -making, adapt to complex tasks, and provide users with authoritative verification results.